ASIF: Coupled Data Turns Unimodal Models to Multimodal without Training
Abstract
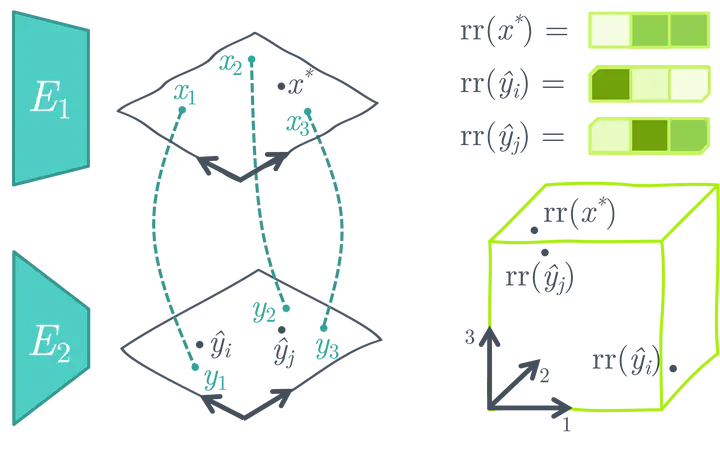
CLIP proved that aligning visual and language spaces is key to solving many vision tasks without explicit training, but required to train image and text encoders from scratch on a huge dataset. LiT improved this by only training the text encoder and using a pre-trained vision network. In this paper, we show that a common space can be created without any training at all, using single-domain encoders (trained with or without supervision) and a much smaller amount of image-text pairs. Furthermore, our model has unique properties. Most notably, deploying a new version with updated training samples can be done in a matter of seconds. Additionally, the representations in the common space are easily interpretable as every dimension corresponds to the similarity of the input to a unique entry in the multimodal dataset. Experiments on standard zero-shot visual benchmarks demonstrate the typical transfer ability of image-text models. Overall, our method represents a simple yet surprisingly strong baseline for foundation multi-modal models, raising important questions on their data efficiency and on the role of retrieval in machine learning.
Valentino Maiorca
Computer Science student @ Sapienza | NLP Engineer @ Babelscape
Excited by Natural Language Understanding, Representation learning and Reasoning.
Luca Moschella
Machine Learning Researcher
I’m excited by many Computer Science fields and, in particular, by Artificial Intelligence.